DB Index를 처음 배우면 이런 생각을 하기 쉽습니다.
“Index를 만들었으니 이 Query는 빨라질 것이다.”
하지만 실무에서는 Index가 있는데도 Query가 느린 경우를 자주 만납니다.
이때 문제를 제대로 보려면 Index 존재 여부가 아니라, Optimizer가 실제로 어떤 Execution plan을 선택했는지를 확인해야 합니다.
Index는 “만들면 무조건 쓰이는 장치”가 아니라, Optimizer가 Cost를 계산해 선택할 수도 있고 선택하지 않을 수도 있는 Access path입니다.
이번 글에서는 DB Index가 있어도 Query가 느려지는 이유를 Selectivity, Composite index, 함수로 감싼 컬럼, Execution plan 관점에서 정리해보겠습니다.

1. Index는 무엇을 빠르게 만드는가?
DB Index는 Table 전체를 처음부터 끝까지 훑지 않고, 조건에 맞는 Row를 더 빠르게 찾기 위한 자료구조입니다.
많은 RDBMS에서 일반적인 Index는 B-tree 계열 구조로 이해할 수 있습니다.
B-tree Index는 정렬된 Key를 따라가며 원하는 범위를 좁혀가므로, 조건에 맞는 Row가 적을수록 효과가 큽니다.
반대로 결과 후보가 Table의 상당 부분이라면 Index를 타고 많은 Row를 찾아가는 Cost가 오히려 커질 수 있습니다.
| 개념 | 의미 |
| Table scan | Table의 많은 Row 또는 전체 Row를 순차적으로 확인하는 접근 |
| Index seek / Range scan | Index를 이용해 특정 값이나 범위를 좁혀 찾는 접근 |
| Selectivity | 조건을 만족하는 Row의 비율, 낮을수록 적은 Row를 고름 |
| Execution plan | DB가 Query를 처리하기 위해 선택한 Access path와 Join 순서 |
여기서 핵심은 Index가 모든 작업을 빠르게 만드는 것이 아니라, “찾아야 할 후보를 충분히 줄일 수 있을 때” 강해진다는 점입니다.
2. 왜 중요한가?
느린 Query를 만났을 때 Index를 하나 더 추가하는 방식은 쉬워 보입니다.
하지만 Index는 읽기 성능만 생각해서 추가할 수 있는 장치가 아닙니다.
Index가 늘어나면 INSERT, UPDATE, DELETE 때마다 Index도 함께 관리해야 하고, 저장 공간과 Cache 사용량도 증가합니다.
잘못 만든 Index는 실제 Query에 쓰이지 않으면서 쓰기 Cost만 늘릴 수 있습니다.
- 운영 DB에서 특정 API 응답 시간이 갑자기 길어질 수 있다.
- Batch 작업이나 관리자 화면에서 Table scan이 반복될 수 있다.
- 불필요한 Index가 많아져 쓰기 성능과 저장 공간이 나빠질 수 있다.
- 면접에서는 “Index가 있으면 빠르다”보다 “언제 쓰이지 않는가”를 설명해야 한다.
따라서 Index 문제는 단순 암기가 아니라 Execution plan을 읽고, 데이터 분포와 Query 조건을 함께 보는 문제입니다.
3. Execution plan으로 먼저 확인하기
Index 관련 문제를 볼 때 가장 먼저 확인할 것은 Execution plan입니다.
Execution plan은 DB가 어떤 Index를 사용했는지, 얼마나 많은 Row를 읽을 것으로 예상했는지, Sort나 Temporary operation이 필요한지를 보여줍니다.
DB 제품마다 출력 형식은 다르지만, 공통적으로 다음 항목을 보면 좋습니다.
| 확인 항목 | 볼 내용 |
| Access method | Table scan인지, Index seek인지, Range scan인지 확인 |
| 사용한 Index | 의도한 Index가 선택됐는지 확인 |
| Estimated rows | DB가 읽어야 한다고 예상한 Row 수가 큰지 확인 |
| Sort / Temporary operation | ORDER BY, GROUP BY 때문에 추가 작업이 생겼는지 확인 |
| Filter predicate | Index로 줄인 뒤 다시 많은 Row를 필터링하는지 확인 |
예를 들어 MySQL 계열에서는 EXPLAIN을, PostgreSQL에서는 EXPLAIN 또는 EXPLAIN ANALYZE를 사용합니다.
EXPLAIN
SELECT *
FROM orders
WHERE status = 'PAID'
AND created_at >= '2026-01-01'
ORDER BY created_at;
예상 결과
의도한 Index를 사용하는지 확인
읽는 Row 수가 충분히 줄어드는지 확인
Sort를 위해 별도 Temporary operation이 필요한지 확인
Execution plan을 보지 않고 “Index가 있으니 괜찮다”고 판단하면 실제 병목을 놓치기 쉽습니다.
4. 그림으로 이해하기
Query가 Index를 효과적으로 쓰는 경우와 그렇지 않은 경우를 단순화하면 다음처럼 볼 수 있습니다.
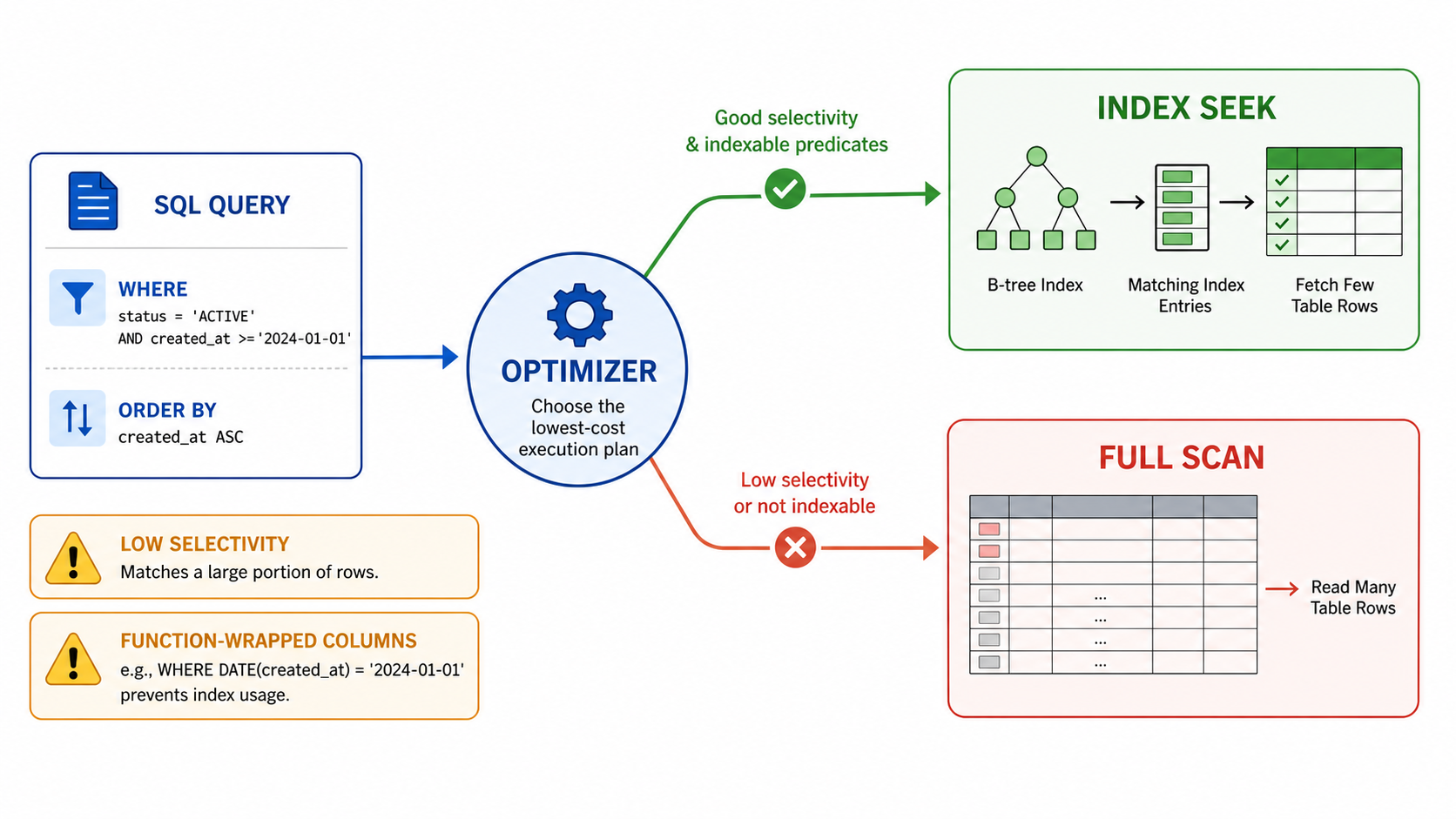
Index seek는 조건에 맞는 후보가 적고, Index key가 Query 조건과 잘 맞을 때 유리합니다.
Table scan은 무조건 나쁜 것이 아닙니다.
읽어야 할 Row가 너무 많거나, Index를 타도 결국 Table의 대부분을 확인해야 한다면 Table scan이 더 합리적인 Plan일 수 있습니다.
5. Selectivity가 낮으면 Index가 약해진다
Selectivity는 조건이 데이터를 얼마나 잘 줄여주는지를 나타냅니다.
예를 들어 사용자 ID는 보통 특정 사용자의 주문만 골라내므로 Selectivity가 좋습니다.
반면 주문 상태가 PAID, READY, CANCELLED처럼 몇 가지 값으로만 나뉘고 각 값에 많은 Row가 몰려 있다면 Selectivity가 낮을 수 있습니다.
CREATE INDEX idx_orders_status ON orders(status);
SELECT *
FROM orders
WHERE status = 'PAID';
예상 결과
status = 'PAID'인 Row가 전체의 대부분이면
Optimizer가 Index보다 Table scan을 선택할 수 있음
Index를 통해 많은 Row id를 찾은 뒤 다시 Table에 접근해야 한다면, 차라리 Table을 순차적으로 읽는 편이 더 저렴할 수 있습니다.
그래서 boolean, 성별, 상태값처럼 값의 종류가 적은 컬럼은 단독 Index로 항상 효과적이라고 보기 어렵습니다.
다만 다른 조건과 함께 Composite index로 묶이면 의미가 달라질 수 있습니다.
6. Composite index는 컬럼 순서가 중요하다
Composite index는 여러 컬럼을 하나의 순서로 묶은 Index입니다.
예를 들어 다음 Index는 user_id를 먼저, created_at을 그다음 기준으로 정렬합니다.
CREATE INDEX idx_orders_user_created
ON orders(user_id, created_at);
이 Index는 특정 사용자의 최근 주문을 찾는 Query에 잘 맞습니다.
SELECT *
FROM orders
WHERE user_id = 42
AND created_at >= '2026-06-01'
ORDER BY created_at;
예상 결과
idx_orders_user_created Index를 이용해
user_id = 42 범위 안에서 created_at 조건을 좁힐 수 있음
하지만 user_id 조건 없이 created_at만 사용하는 Query라면 상황이 달라집니다.
SELECT *
FROM orders
WHERE created_at >= '2026-06-01';
예상 결과
Composite index의 선두 컬럼인 user_id 조건이 없으므로
Index를 기대한 방식으로 활용하지 못할 수 있음
이를 흔히 Leftmost prefix rule로 설명합니다.
Composite index는 왼쪽부터 정렬된 구조이므로, 앞쪽 컬럼을 건너뛰고 뒤쪽 컬럼만으로 항상 효율적인 탐색을 기대하기 어렵습니다.
7. 컬럼을 함수로 감싸면 Index를 못 탈 수 있다
Index가 있어도 WHERE 절에서 컬럼을 함수로 감싸면 문제가 생길 수 있습니다.
다음 Query는 created_at Index가 있더라도 DB가 Index에 저장된 원래 값을 그대로 비교하기 어렵게 만듭니다.
CREATE INDEX idx_orders_created_at
ON orders(created_at);
SELECT *
FROM orders
WHERE DATE(created_at) = '2026-06-26';
예상 결과
일반 Index를 효율적으로 사용하지 못하고
많은 Row에 DATE(created_at)을 적용한 뒤 비교할 수 있음
이럴 때는 컬럼을 함수로 감싸기보다 범위 조건으로 바꾸는 편이 안전합니다.
SELECT *
FROM orders
WHERE created_at >= '2026-06-26 00:00:00'
AND created_at < '2026-06-27 00:00:00';
예상 결과
created_at Index의 정렬 순서를 이용해
해당 날짜 범위만 탐색할 가능성이 커짐
물론 DB에 따라 Function-based index나 Expression index를 만들 수 있습니다.
하지만 기본적인 Tuning 사고방식은 “Index 컬럼을 계산 결과로 바꾸기 전에, Range condition으로 표현할 수 있는가”를 먼저 보는 것입니다.
8. ORDER BY와 LIMIT도 함께 봐야 한다
Index는 WHERE 조건만을 위한 장치가 아닙니다.
Sort order와 LIMIT에도 영향을 줍니다.
예를 들어 특정 사용자의 최신 주문 20개를 가져오는 Query가 있다고 해보겠습니다.
CREATE INDEX idx_orders_user_created_desc
ON orders(user_id, created_at);
SELECT *
FROM orders
WHERE user_id = 42
ORDER BY created_at DESC
LIMIT 20;
예상 결과
user_id 조건으로 범위를 좁힌 뒤
created_at 순서로 필요한 20개를 빠르게 찾을 수 있음
반대로 WHERE에는 맞는 Index가 있어도 ORDER BY를 처리하기 위해 별도 Sort가 필요하면 Query가 느려질 수 있습니다.
Execution plan에서 filesort, sort, temporary 같은 표현이 보이면 Sort cost도 함께 확인해야 합니다.
Index 설계는 조건 컬럼만 보는 것이 아니라 자주 쓰는 Query pattern 전체를 봐야 합니다.
9. 실무에서 보는 점검 순서
느린 조회를 만났을 때는 다음 순서로 점검하면 원인을 좁히기 좋습니다.
- 실제 느린 SQL과 Binding value를 확인한다.
- EXPLAIN 또는 EXPLAIN ANALYZE로 Execution plan을 본다.
- 사용한 Index, Estimated rows, Actual rows를 확인한다.
- WHERE 조건의 Selectivity가 충분한지 확인한다.
- Composite index의 컬럼 순서가 Query pattern과 맞는지 확인한다.
- 컬럼에 함수, Type casting, 연산이 걸려 Index 사용을 방해하지 않는지 확인한다.
- ORDER BY, GROUP BY, LIMIT 때문에 추가 Sort나 Temporary operation이 생기는지 확인한다.
- Index를 추가하기 전에 기존 Index로 대체 가능한지 확인한다.
운영 환경에서는 테스트 데이터와 실제 데이터 분포가 다를 수 있습니다.
개발 DB에서는 빠른 Query가 운영 DB에서는 느릴 수 있는 이유도 여기에 있습니다.
특히 status, category, deleted 여부처럼 값의 분포가 한쪽으로 치우친 컬럼은 실제 Statistics와 Execution plan을 함께 봐야 합니다.
10. 실무 관점
실무에서 Index tuning을 할 때 가장 위험한 습관은 “느리면 Index 추가”라고 바로 결론 내리는 것입니다.
Index는 문제를 해결할 때도 많지만, Query pattern을 이해하지 못한 상태에서 추가하면 시스템 전체 Cost를 숨겨진 방식으로 늘립니다.
특히 운영 DB에서는 읽기 하나만 빨라지는 대신 쓰기, 저장 공간, Cache 효율, 배포 후 유지보수 부담이 함께 바뀝니다.
그래서 Index를 설계할 때는 단일 Query의 속도보다 “이 Index가 우리 서비스의 반복 Query pattern을 얼마나 설명하는가”를 먼저 봐야 한다고 생각합니다.
11. 면접 질문 예시
11-1. Index가 있는데도 Query가 느릴 수 있는 이유는 무엇인가요?
Index의 Selectivity가 낮거나, Composite index의 선두 컬럼을 사용하지 않거나, 컬럼을 함수로 감싸 Index를 효율적으로 쓰지 못할 수 있습니다.
또한 Index를 사용하더라도 읽어야 할 Row가 많거나 Sort cost가 크면 전체 Query는 여전히 느릴 수 있습니다.
11-2. Composite index에서 컬럼 순서가 중요한 이유는 무엇인가요?
Composite index는 지정한 컬럼 순서대로 정렬된 구조입니다.
따라서 앞쪽 컬럼 조건 없이 뒤쪽 컬럼만으로는 원하는 범위를 효율적으로 좁히기 어려울 수 있습니다.
11-3. Execution plan에서 무엇을 확인해야 하나요?
Table scan인지 Index seek인지, 어떤 Index를 사용했는지, Estimated rows가 얼마나 되는지, Sort나 Temporary operation이 발생하는지 확인해야 합니다.
가능하다면 Runtime statistics까지 확인해 Optimizer의 예상과 실제 데이터 분포가 크게 다른지도 봐야 합니다.
12. 정리
- Index는 만들었다고 항상 쓰이는 것이 아니라 Optimizer가 Cost를 보고 선택한다.
- Selectivity가 낮은 조건은 Index를 사용해도 충분히 빠르지 않을 수 있다.
- Composite index는 컬럼 순서와 실제 WHERE, ORDER BY 패턴이 맞아야 효과적이다.
- 컬럼을 함수나 연산으로 감싸면 일반 Index를 효율적으로 못 탈 수 있다.
- 느린 Query는 Index 추가 전에 Execution plan과 실제 데이터 분포를 먼저 확인해야 한다.
DB 성능 문제를 잘 본다는 것은 Index 문법을 많이 아는 것보다, Query 조건과 데이터 분포, Execution plan을 함께 읽는 일에 가깝습니다.
'CS' 카테고리의 다른 글
| TCP 3-way handshake 쉽게 이해하기 (0) | 2026.06.30 |
|---|---|
| Race condition이란? 동시성 버그와 임계 구역 이해하기 (0) | 2026.06.23 |
| 운영체제 데드락 쉽게 정리하기 (0) | 2026.06.19 |